
Essa técnica pode levar a veículos autônomos mais seguros, headsets AR/VR mais eficientes ou robôs de armazém mais rápidos.
Imagine dirigir por um túnel em um veículo autônomo, mas, sem você saber, um acidente interrompeu o trânsito à frente. Normalmente, você precisaria confiar no carro à sua frente para saber que deveria começar a frear. Mas e se o seu veículo pudesse ver ao redor do carro à frente e pisar no freio ainda mais cedo?
Pesquisadores do MIT e Meta desenvolveram uma técnica de visão computacional que algum dia poderá permitir que um veículo autônomo faça exatamente isso.
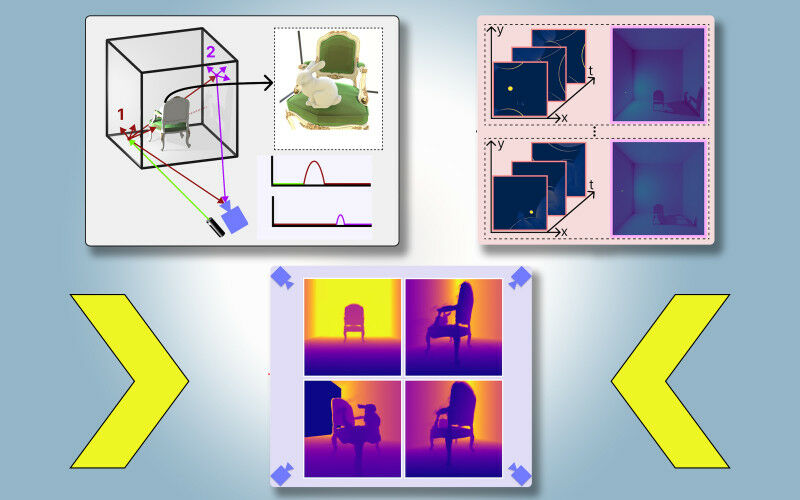
Eles introduziram um método que cria modelos 3D fisicamente precisos de uma cena inteira, incluindo áreas bloqueadas de visualização, usando imagens de uma única posição de câmera. Sua técnica usa sombras para determinar o que está nas partes obstruídas da cena.
Eles chamam sua abordagem de PlatoNeRF, baseada na alegoria da caverna de Platão, uma passagem da “República” do filósofo grego em que prisioneiros acorrentados em uma caverna discernem a realidade do mundo exterior com base nas sombras projetadas na parede da caverna.
Ao combinar a tecnologia lidar (detecção e alcance de luz) com aprendizado de máquina, PlatoNeRF pode gerar reconstruções mais precisas da geometria 3D do que algumas técnicas de IA existentes. Além disso, PlatoNeRF é melhor na reconstrução suave de cenas onde as sombras são difíceis de ver, como aquelas com muita luz ambiente ou fundos escuros.
Além de melhorar a segurança dos veículos autônomos, o PlatoNeRF poderia tornar os headsets AR/VR mais eficientes, permitindo ao usuário modelar a geometria de uma sala sem a necessidade de andar por aí fazendo medições. Também poderia ajudar os robôs de armazém a encontrar itens em ambientes desordenados com mais rapidez.
“Nossa ideia principal era pegar essas duas coisas que já foram feitas em disciplinas diferentes antes e juntá-las – lidar multibounce e aprendizado de máquina. Acontece que quando você junta essas duas coisas, é quando você encontra muitas novas oportunidades para explore e obtenha o melhor dos dois mundos”, diz Tzofi Klinghoffer, estudante de pós-graduação em artes e ciências de mídia do MIT, afiliado do MIT Media Lab e autor principal de um artigo sobre PlatoNeRF.
Klinghoffer escreveu o artigo com seu orientador, Ramesh Raskar, professor associado de artes e ciências da mídia e líder do Camera Culture Group do MIT; autor sênior Rakesh Ranjan, diretor de pesquisa de IA do Meta Reality Labs; bem como Siddharth Somasundaram do MIT, e Xiaoyu Xiang, Yuchen Fan e Christian Richardt da Meta. A pesquisa será apresentada na Conferência sobre Visão Computacional e Reconhecimento de Padrões.
Lançando luz sobre o problema
Reconstruir uma cena 3D completa a partir do ponto de vista de uma câmera é um problema complexo.
Algumas abordagens de aprendizado de máquina empregam modelos generativos de IA que tentam adivinhar o que está nas regiões oclusas, mas esses modelos podem alucinar objetos que realmente não estão lá. Outras abordagens tentam inferir as formas de objetos ocultos usando sombras em uma imagem colorida, mas esses métodos podem ter dificuldades quando as sombras são difíceis de ver.
Para PlatoNeRF, os pesquisadores do MIT desenvolveram essas abordagens usando uma nova modalidade de detecção chamada lidar de fóton único. Os Lidars mapeiam uma cena 3D emitindo pulsos de luz e medindo o tempo que essa luz leva para retornar ao sensor. Como os lidars de fóton único podem detectar fótons individuais, eles fornecem dados de maior resolução.
Os pesquisadores usam um lidar de fóton único para iluminar um ponto alvo na cena. Alguma luz reflete nesse ponto e retorna diretamente para o sensor. No entanto, a maior parte da luz se espalha e reflete em outros objetos antes de retornar ao sensor. PlatoNeRF depende desses segundos reflexos de luz.
Ao calcular quanto tempo leva para a luz refletir duas vezes e depois retornar ao sensor lidar, o PlatoNeRF captura informações adicionais sobre a cena, incluindo profundidade. O segundo reflexo de luz também contém informações sobre sombras.
O sistema rastreia os raios de luz secundários – aqueles que refletem no ponto alvo para outros pontos da cena – para determinar quais pontos estão na sombra (devido à ausência de luz). Com base na localização dessas sombras, PlatoNeRF pode inferir a geometria de objetos ocultos.
O lidar ilumina sequencialmente 16 pontos, capturando múltiplas imagens que são usadas para reconstruir toda a cena 3D.
“Cada vez que iluminamos um ponto na cena, estamos criando novas sombras. Como temos todas essas diferentes fontes de iluminação, temos muitos raios de luz disparando ao redor, então estamos esculpindo a região que está oculta e fica além do olho visível”, diz Klinghoffer.
Uma combinação vencedora
A chave para PlatoNeRF é a combinação de lidar multibounce com um tipo especial de modelo de aprendizado de máquina conhecido como campo de radiância neural (NeRF). Um NeRF codifica a geometria de uma cena nos pesos de uma rede neural, o que dá ao modelo uma forte capacidade de interpolar ou estimar novas visualizações de uma cena.
Essa capacidade de interpolar também leva a reconstruções de cena altamente precisas quando combinada com lidar multibounce, diz Klinghoffer.
“O maior desafio foi descobrir como combinar essas duas coisas. Nós realmente tivemos que pensar sobre a física de como a luz é transportada com lidar multibounce e como modelar isso com aprendizado de máquina”, diz ele.
Eles compararam o PlatoNeRF a dois métodos alternativos comuns, um que usa apenas lidar e outro que usa apenas NeRF com imagem colorida.
Eles descobriram que seu método foi capaz de superar ambas as técnicas, especialmente quando o sensor lidar tinha resolução mais baixa. Isso tornaria sua abordagem mais prática para implantação no mundo real, onde sensores de resolução mais baixa são comuns em dispositivos comerciais.
“Há cerca de 15 anos, nosso grupo inventou a primeira câmera para ‘ver’ os cantos, que funciona explorando múltiplos reflexos de luz, ou ‘ecos de luz’. Essas técnicas usaram lasers e sensores especiais e usaram três reflexos de luz. Desde então, a tecnologia lidar se tornou mais popular, o que levou à nossa pesquisa sobre câmeras que podem ver através do nevoeiro. a relação sinal-ruído é muito alta e a qualidade da reconstrução 3D é impressionante”, diz Raskar.
No futuro, os pesquisadores querem tentar rastrear mais de dois reflexos de luz para ver como isso poderia melhorar as reconstruções de cenas. Além disso, eles estão interessados em aplicar técnicas de aprendizado mais profundo e combinar PlatoNeRF com medições de imagens coloridas para capturar informações de textura.
“Embora as imagens de sombras da câmera tenham sido estudadas há muito tempo como um meio de reconstrução 3D, este trabalho revisita o problema no contexto do lidar, demonstrando melhorias significativas na precisão da geometria oculta reconstruída. O trabalho mostra como algoritmos inteligentes podem permitir capacidades extraordinárias quando combinado com sensores comuns – incluindo os sistemas lidar que muitos de nós carregamos agora no bolso”, diz David Lindell, professor assistente do Departamento de Ciência da Computação da Universidade de Toronto, que não esteve envolvido neste trabalho.